如何理解判别模型和生成模型?
在机器学习中,模型可以分为两种:判别模型和生成模型。两者的区别在于找到决策边界的过程不同:
下面就来进一步解释下其中的细节。
垃圾邮件分类是机器学习中常用的例子,本文以此为例来进行讲解:
这里为了简化问题,我们用作例子的垃圾邮件分类数据集中只包含一个特征,就是邮件正文的长度。普通邮件用正类
从上图可以看出,垃圾邮件(也就是负类
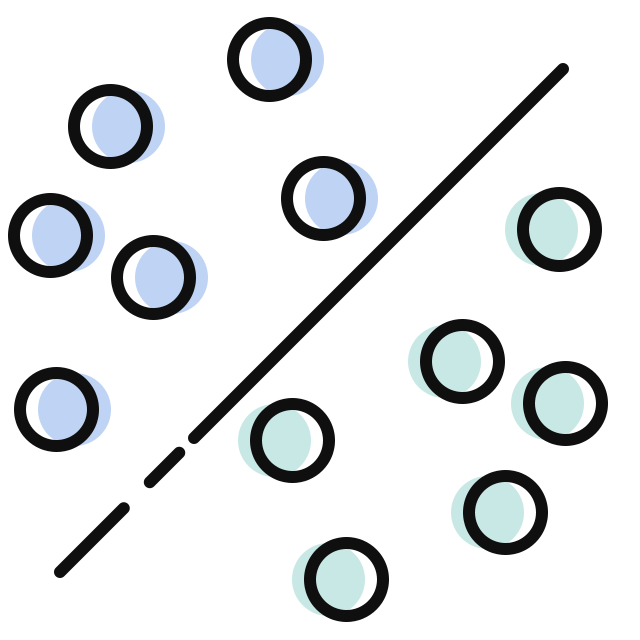
先来看看判别模型如何进行垃圾邮件分类。比如感知机模型就是一种判别模型,它的算法是尽可能找到犯错最少的位置作为决策边界。在垃圾邮件分类数据集上,下面两条虚线都只犯了一个错(图中的黑色虚线表示决策边界,周围的红色和蓝色虚线指出哪侧是正类
除了感知机外,我们课程中介绍过的逻辑回归、支持向量机这些也是判别模型,只是对错误的定义不一样:
感知机
逻辑回归
软间隔支持向量机
这三者的共同点就是都是通过数据集,尽可能找到犯错最少的位置(也就是“经验误差最小原则”)作为决策边界:
因为是通过判别错误来得到决策边界的,所以都称为判别模型(Discriminative model)。
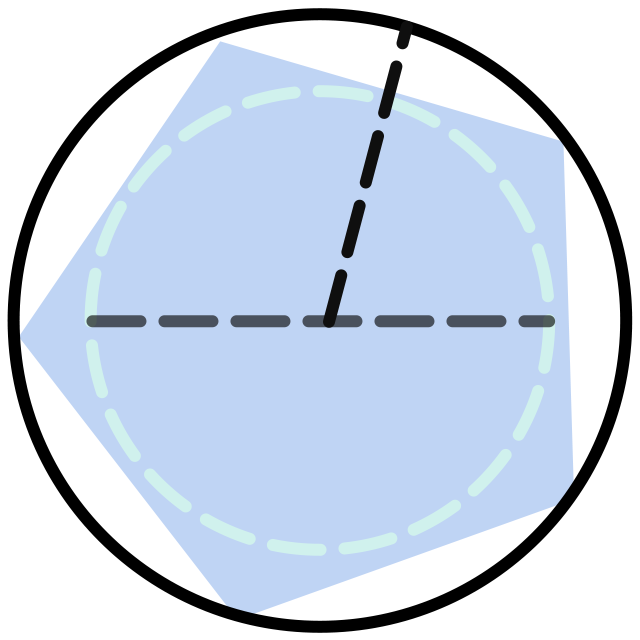
其实还有另外一种思考方向,比如我们猜测正、负类都分别符合某正态分布,那么根据数据集可以算出这两个分布的参数
就上图而言,可以将这两个分布的交点作为边界(这里有很多细节,我们后面再讨论),这是因为当某点出现在决策边界左侧时,根据正、负类的正态分布,该点为正类的概率更大;同理在右侧的话,为负类的概率更大。比如下图中的
这种先根据数据集生成正、负类的分布,再得到决策边界的模型就称为生成模型(Generative model):
判别模型和生成模型的区别如下:
可见,生成模型多了生成正、负类分布的过程,而这个过程就是在尝试学习这些数据到底是怎么生成的,或者说在尝试学习真正的知识。可以这么比喻,判别模型就是不断刷题,不太去理解,这样也可以很好地应付考试(预测);而生成模型在刷题同时还会尝试理解其中的知识,只要理解得当,完全可以考出好的成绩:
从上面的比喻出发,可以进一步理解两者的优劣:
(1)刷得题够多,考试成绩就会很好;但如果有些题型没有刷到就会束手无策。也就是说,判别模型只要数据量足够就有很好的泛化能力,但如果遇到没有出现过的情况,那么是无法解决的,这样的例子后面会看到。
(2)理解如果出错,考试反而糟糕;但是如果能够正确理解,那么在刷题量不够的情况下,也可以举一反三,甚至可以解决没有遇到过的题型。也就是说,数据量少的时候,生成模型可能有奇效,甚至可以解决历史上没有出现过的问题。